Nearform’s LLM Playground: We created our version of the OpenAI Playground
Exploring the exciting world of Large Language Models (LLMs)

At Nearform, we're always on the lookout for emerging technologies that have the potential to wow our customers and transform their organisations. Just like how we became big supporters of Node.js in its early days, we're now diving into the realm of Large Language Models (LLM) powered applications.
Now, you might be wondering what LLM-powered applications are all about. Well, imagine applications like ChatGPT that use language models to generate responses. It's pretty awesome, right? But here's where it gets even more interesting — when we integrate these LLM agents with our existing tools, APIs and databases, it takes everything to the next level. We can build specialised tools where the LLM plays a crucial yet small part.
The goal of our latest project was to create our own version of the OpenAI Playground. It was a fantastic opportunity for us to dive deep into the code and see how much additional work we needed to do on top of the OpenAI API. How far could we push this? Plus, it laid a solid foundation for our teams to build future LLM-powered products.
The Playground
The initial steps were straightforward. We used LangChain.js, a handy wrapper for the LLM API, and built a simple REST API using Fastify to expose the necessary parameters.
Nothing too complex... until we started working on supporting long conversations, fine-tuning responses to specific goals and integrating with external APIs and tools. That's when things got really interesting.
But before we delve deeper into the technicalities, let's take a quick tour of Nearform’s LLM Playground and its different components.
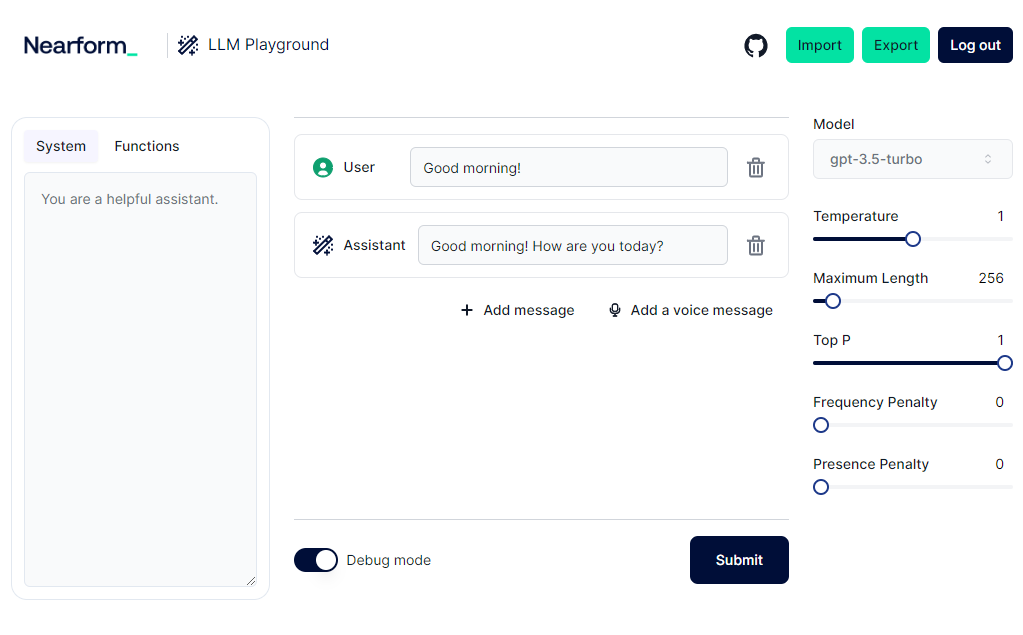
Starting from the top bar, we built the ability to import and export all data in the playground. This feature has been a lifesaver when collaborating on refining prompts and testing out new ideas.
On the right sidebar, we have parameters that control how the LLM generates replies. These are parameters specific to the OpenAI API and we merely proxy them through. Changing the model’s parameters can greatly impact its ability, performance, and maximum conversation length. Then we have temperature and TopP, which determine the level of randomness in the replies, and penalties, which further refine the responses.
In the central section of the page, we have the message history. Each message plays a specific role — it can be a User asking a question, an Assistant replying, or even a special Function reply (we'll come back to that later). We can edit the full history and modify the replies provided by the Assistant. This feature is invaluable for reproducing edge cases without having to retry the conversation multiple times until we achieve a specific response.
Now, let's focus on the leftmost section — the System. This is where we give instructions to the LLM Assistant about its goal and behaviour. It can be as simple as saying "You are a helpful assistant," or we can get creative and ask it to reply in different languages or even pirate dialects (arr, matey!). But it doesn't stop there — we can demand structured data back from the model, specify JSON schemas and indicate the types of responses we're willing to accept. It's like having a genie that grants our data-related wishes.
One key limitation of most LLMs is that they don't have access to live data and lack awareness of the current time. If you need to consider temporal references in its responses, tough luck! But fear not, we have a solution: functions. Functions allow the LLM to interact with the outside world, perform searches on Google, access internal APIs and databases, or even ask for the current time. They provide the agent with more context and are the secret sauce behind the scenes. To keep things neat, we have a handy debug button to test the conversation without functions interfering.
LangChain.js
In this project, we didn’t use the OpenAI client directly. Instead, we used LangChain, which in turn uses the OpenAI client. There are multiple LLM providers out there and at the core functionality they are very similar but they all have their own additional specific features.
LangChain aims to be the library that normalises all these features and allows us to be (mostly) provider-agnostic when implementing an LLM app. Not only that, but LangChain is also a great learning tool when it comes to providing prompt engineering examples. To implement some missing features, LangChain leverages the LLMs themselves and through the use of creative prompts it backfills the features.
Memory and long conversation chains
Now, let's address an interesting challenge we encountered — long conversation chains. The OpenAI API has a maximum capacity for processing requests, and anything beyond that results in an error. Interestingly, capacity isn't measured in characters or bytes but in tokens. Tokens can vary in size depending on the content — for example, uppercase words consume more tokens than lowercase ones (capital letters be greedy!). In general, we can consider a token to be 4 characters in the English language.
Different OpenAI models will have different limits, but it’s safe to say that the higher the limit the more expensive each API call will be. For example, at the time of writing, GPT-4 has a limit of 8,192 tokens whereas the much cheaper GTP-3 Turbo has a limit of only 4,096 tokens. This means that for any practical application, these limits are fairly quick to reach, leading to application errors.
At first, we simply showed the error to the user. Our next approach was to remove the oldest messages from the chain to make it work. However, this approach meant losing important context from those removed messages. So, we set out to find a better solution.
LangChain implements the concept of memory. LangChain has multiple memory types but the one we found most interesting was the conversation summary buffer. This memory strategy keeps the most recent messages in full but summarises the older ones. This ensures we keep all the details and context for recent messages while still keeping some of the most relevant details on the old ones.
LangChain doesn't rely on complex code to parse the message history and extract context. Instead, it cleverly uses the LLM itself in a parallel conversation thread. It sends the first few messages and asks the LLM to generate a compact conversation history with all relevant context. It’s the LLM itself that generates the summary.
Assistants, Functions and Agents
LLMs, or Language Models, have limitations when it comes to calling third-party APIs and accessing real-time data. They rely solely on the information they were trained on and cannot even determine the current time. However, there is a solution called Functions that can help overcome these challenges. Functions allow us to call third-party APIs when necessary.
For example, if you ask an LLM about the weather in London or Bristol, it will give a generic response stating that it doesn't have access to real-time data. But we can teach the LLM to recognise when it should call a weather API. Then, using our application code, we can make the API call ourselves and provide the LLM with the additional information it needs.
There are several challenges the LLM must overcome to implement functions:
The LLM must be aware that there is a weather API and has to be able to determine when it would be appropriate to call it
The LLM needs to provide structured data as a JSON object with the required parameters for the API so that we call it from our own server
The LLM must parse the API reply we provide and generate an appropriate reply with that information
This article explains how the Agent model can be implemented in only 100 lines of code.
Previously, LangChain supported this functionality through Agents and Tools, which was a creative approach. However, now OpenAI has optimised the process and their LLM API has built-in support for Functions and Assistants.
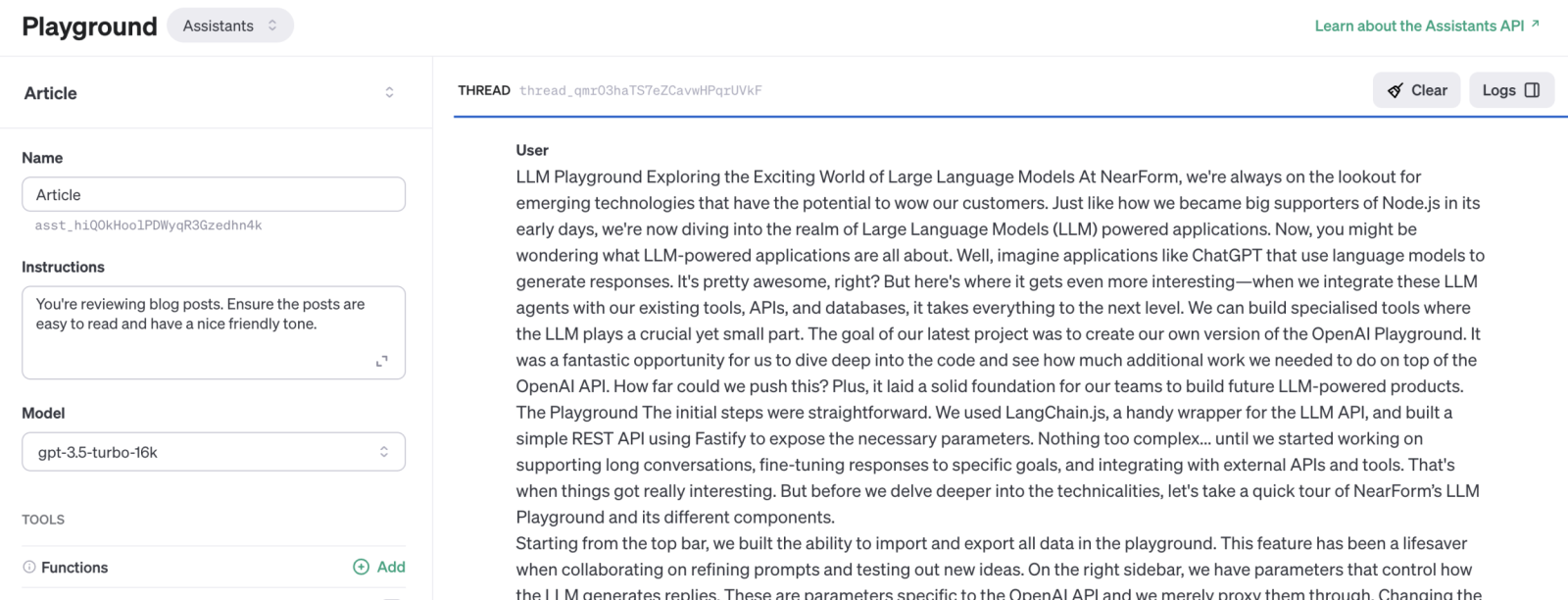
Functions aren't just useful for calling third-party APIs. They can be even more powerful. We can utilise them to answer questions with structured data or guide the conversation to collect the necessary information for our app workflow.
Let's say we're using the LLM to support a user's onboarding process in a web application. We need to gather multiple data points from the user like their first name, surname, date of birth and email address. With Functions, we can define a schema for a user and instruct the LLM to use that function.
Now, the LLM will keep the conversation going until it gathers all the required data points. It can generate appropriate questions to collect the missing information and review the conversation history to determine what's missing next. The real value lies in the LLM understanding the context and gathering the necessary data on its own.
Streaming
LLMs face a significant challenge — they tend to be quite slow in responding. It can take a few seconds for them to reply to most requests. However, here's the good news: LLMs don't need all that time to generate a complete reply. They actually analyse the entire context and generate one additional piece of information at a time. They keep doing this recursively until they sense it's time to stop.
Now, let's talk about reading speed. On average, an adult can comfortably read around 5 words per second. However, even at a pace of 4 or 3 words per second, it still feels comfortable to read. It's only when we have to wait for a reply for a longer time that it becomes uncomfortable.
The cool part is that we can make use of this knowledge to enhance the conversation experience. Instead of delivering the entire reply at once, we can stream it a few tokens at a time. By doing this, we can make the interaction feel more like a real conversation.
Conclusion
There you have it: the exciting world of the LLM Playground. It's a place where developers and business people alike can explore the power of Large Language Models and how they can be harnessed to build amazing software.
Creating this application allowed us to get a deeper understanding of how non-trivial aspects of LLMs work, and how frameworks such as LangChain are built.
We believe that nowadays it’s essential for companies to stay on top of the current AI trends, as the landscape is in constant and rapid evolution, and new approaches to solving problems are researched, discovered and published regularly.
LLMs open up a great variety of opportunities for software creators and users alike, and keeping ourselves up to date with industry trends allows us to chase opportunities as they show up.


Insight, imagination and expertly engineered solutions to accelerate and sustain progress.
Contact