How to create a GenAI agent using Semantic Kernel
Our example sets an AI agent the aim of retrieving, calculating and plotting financial data

In this article, we explore what Microsoft's Semantic Kernel is, what the advantages of using it are, and provide a simple example of how to use Semantic Kernel to create an AI agent to accomplish the task of displaying different value graphs for a stock in a specific time period.
This provides a reasonably complex example that uses external data sources and custom data formatting.
What is Semantic Kernel?
Microsoft’s Semantic Kernel is a software development kit (SDK) that integrates Large Language Models (LLMs) with programming languages like C#, Python, and Java. The SDK does this by allowing us to define programming functions as plugins that can be easily chained together in a few lines of code.
Another major feature of Semantic Kernel is its ability to automatically orchestrate (or coordinate) plugins using AI. Simply provide the Semantic Kernel with an LLM and the plugins you need, then create a planner. When you ask the planner to achieve a specific goal, the Semantic Kernel will execute the plan for you.
What is an AI agent?
An AI agent is a software program designed to perform tasks autonomously to achieve predetermined goals. It interacts with its environment (such as code functions, APIs, and data sources) and independently determines the best tools and actions to use for each task. AI agents can adapt to changes in their environment, learn from experiences, and improve their performance over time.
In summary, the user provides the goal which the AI should achieve and the AI will determine and execute the best approach to achieving that result.
AI agent: Financial stock plotter
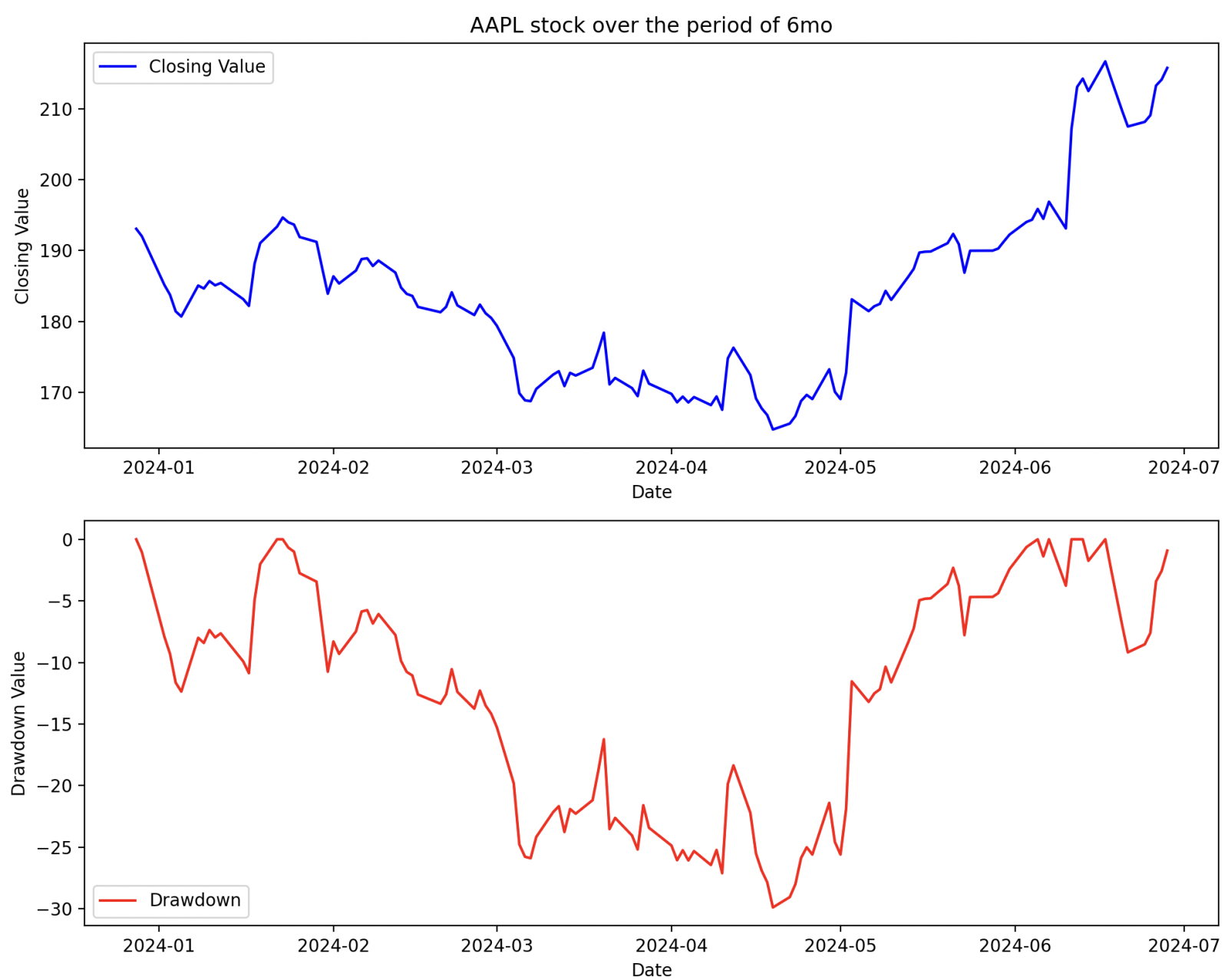
We utilised Semantic Kernel to create an AI agent. The aim of the agent is to retrieve financial data, calculate the drawdown of the data, and finally plot both the data and the drawdown.
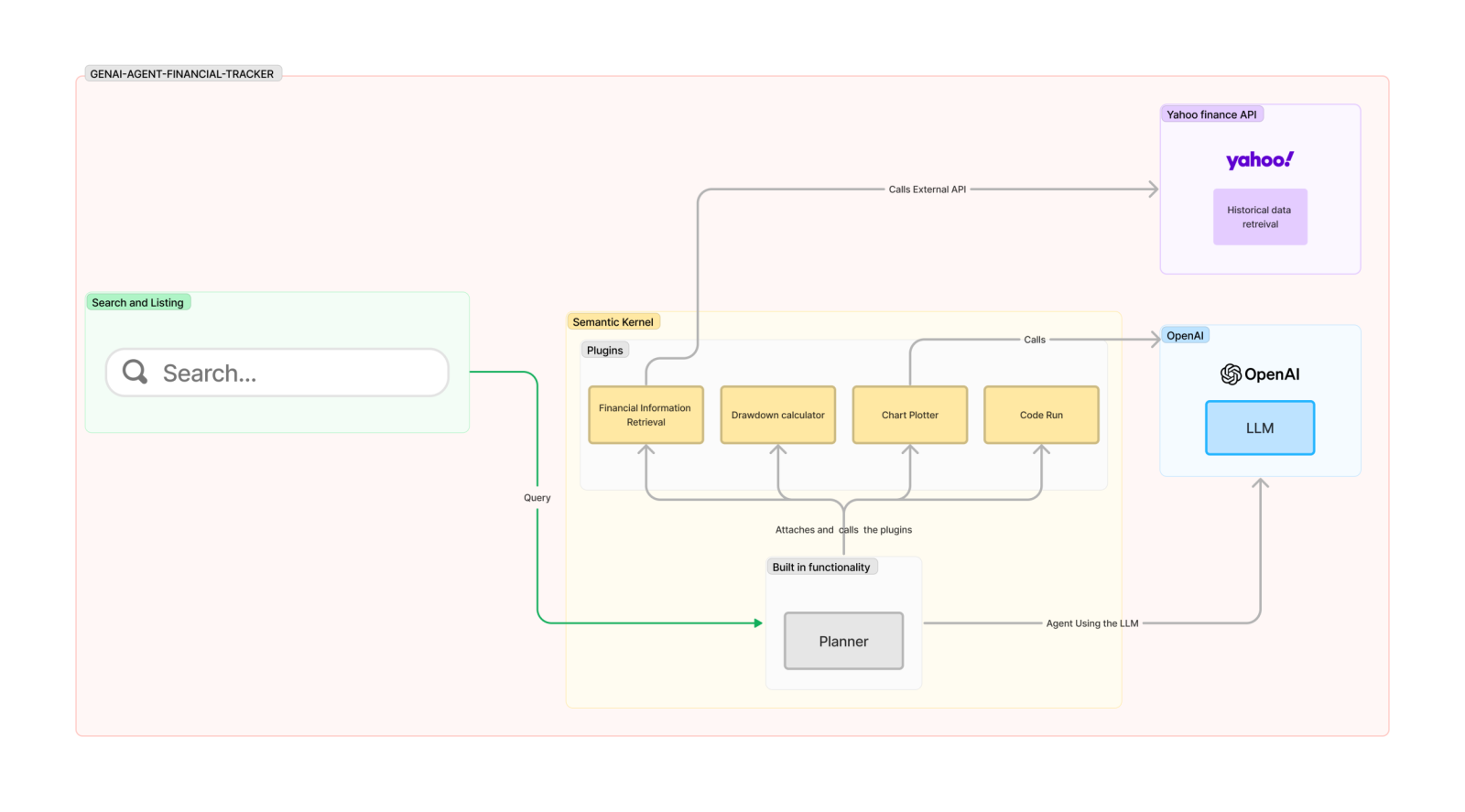
The above diagram shows how the agent communicates with the required APIs and functions to perform the desired tasks. A step-by-step explanation is available below:
1. The user asks a question via the terminal: User: give me details on Apple over the last 6 months
2. The agent will process the query to retrieve the required fields from the user’s query:
a. ticker_name: AAPL
b. period: 6mo
3. The agent will call a function to retrieve the historical data from the Yahoo finance API. This data includes a variety of information on the stock over the period provided. The values we are interested in are: date and close
a. date: the day the stock values were at the level indicated
b. close: the value of the stock at the time of closing of the financial markets on that day
4. The agent will call a function to calculate the drawdown
a. The drawdown is a financial measure that looks at the price of a stock at a certain point in time, gets the previous max value the stock held, and subtracts the max from the current value. The drawdown is a negative score as the current value is never greater than the cumulative max value up to the date we are looking at. The closer the drawdown is to zero, the closer the stock is to its maximum value.
5. The agent will then generate dynamic Python code to plot the data in a valid format using pandas and matplotlib.
6. Finally, the agent will refactor the code to attach the data calculated earlier on to the code just generated, then execute it
Creating an agent
At the time of writing, Semantic Kernel allows four types of agents, called planners.
Sequential planner
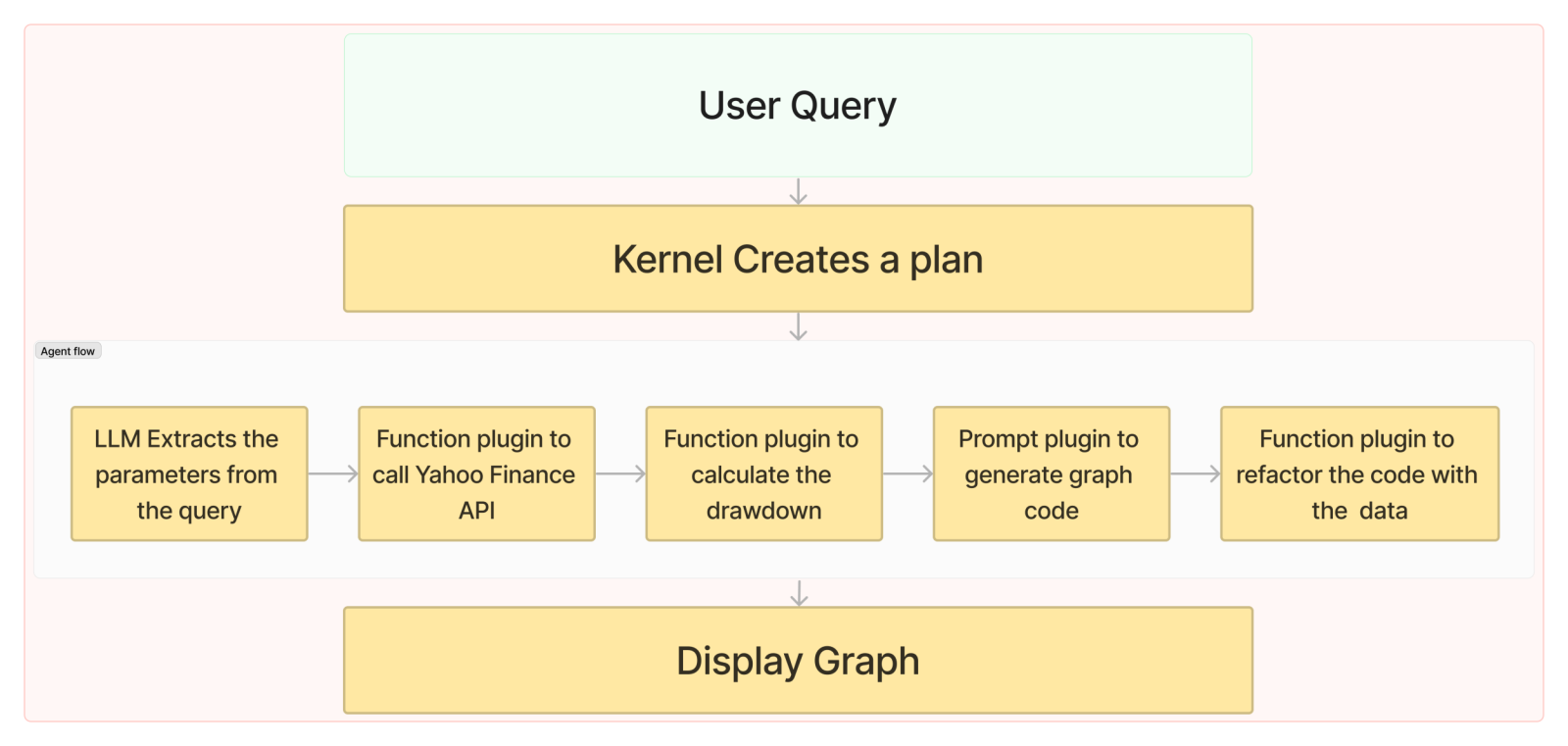
Sequential planner takes a goal (prompt) and runs through the plugins provided to the agent at creation time, in the order requested by the goal. The loop will continue until the goal is complete. This is the agent we used to accomplish our goal.
The process our planner follows is shown below:
Stepwise planner
An agent that will run through the user request and process it step by step. It differs from the sequential planner by only running a specific agent against a part of the query. This allows the agent to break down the query into individual parts and run those against the plugin.
An example is if we asked “What would be the temperature in New York if we added 10 degrees to the current temperature?” the stepwise planner will be able to split the weather API call and the math problem from the query and run them separately, giving answers based on them.
Handlebar planner
The main advantage of the handlebar planner over the stepwise planner is the usage of the handlebar templating language to generate the plan. This is due to the majority of LLMs already supporting the handlebar interface when dealing with prompts, which helps provide improve the accuracy of the response (in this case the agent plan). In opposition to the stepwise planner that uses XML when generating the plan. Using this language we can also provide loops and conditions that otherwise would only be available in coding languages.
Another advantage of this planner is the fact that the return value of the serialised function planner.getPlan is a readable text file that can be stored and reloaded at a later date. However, this planner is not available in the Python version of the kernel, as of the time of writing.
Custom planner
Semantic Kernel offers us the ability to create our agent with custom rules. This involves more complexity but also gives more freedom to the developer to create the agent in the way they intend. It is particularly useful when you want human intervention during the agent planning stages, for example, to provide new variables or access custom data sources.
At the time of writing, the team behind Semantic Kernel intends to deprecate the Handlebar and Stepwise planners, in favour of this approach.
Our agent
The below code demonstrates how we created our agent using the Sequential planner:
from semantic_kernel import Kernel
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion, OpenAIChatPromptExecutionSettings
from semantic_kernel.functions import KernelArguments
from semantic_kernel.connectors.ai.function_call_behavior import FunctionCallBehavior
from plugins import CodeRefactor, FinancePlugi
from semantic_kernel.planners import SequentialPlanner
# Create the Kernel Instance
kernel = Kernel()
execution_settings = OpenAIChatPromptExecutionSettings(
service_id="chat"
)
# Configure AI service used by the kernel
kernel.add_service(
OpenAIChatCompletion(service_id=service_id,
api_key=open_ai_key,
ai_model_id=ai_model_id),
)
# Adding our custom plugins to the kernel
kernel.add_plugin(parent_directory="./plugins", plugin_name="ChatPlugin")
kernel.add_plugin(plugin=FinancePlugin(), plugin_name="FinancePlugin")
kernel.add_plugin(parent_directory="./plugins", plugin_name="ChartPlugin")
kernel.add_plugin(plugin=CodeRefactor(), plugin_name="CodePlugin")
# Define the details to be passed to the planner
arguments = KernelArguments(settings=execution_settings)
arguments["user_input"]= "Show me the drawdown for Apple stock"
goal = '''Based on the user_input argument,chat with the AI to get
the ticker_name and period if available,
extract the data for a ticker over time,
create a drawdown, plot the chart,
refactor the code to include the drawdown data.
'''
# Create the plan
plan = await planner.create_plan(goal = goal)
# Execute the plan
result = await plan.invoke(kernel=kernel, arguments=arguments)Steps to create an AI agent
Create the kernel Instance: This is the starting point to map our planner to the plugins and LLM. We can generate more than one planner with the same kernel, allowing for parallel agents if needed.
Configure AI service used by the kernel: This allows the tool to interpret user input into the right parameters and ensure the right tool is called at the right time to accomplish the goal.
Adding our custom plugins to the kernel: This enables non-standard LLM calls to be usable by our agent
Define the details to be passed to the planner: These include standard LLM settings (temperature, token limit, …) and function handling instructions.
Create the Plan: Define the “System Message” for the planner as the goal. This instructs the LLM about the behaviour we expect our agent to have. The goal should be straightforward and use similar terminology available in the tools' descriptions.
Execute the plan: Connects the details defined in step 4 to the plan and triggers the invocation step for the plan to start.
Plugins
A Semantic Kernel plugin is a software component designed to extend the LLM's functionality by either granting the LLM capabilities that it did not previously have (code plugins) or defining the purpose of the LLM invocation to a specific topic (prompt plugins).
In contrast to tools supported natively by the LLM (such as function invocation), a plugin is not attached directly to the model but is placed within the planner. The planner will then generate a step-by-step approach and see if any of the steps of the goal are associated with the plugin and will call the function in question.
The main drawback of plugins is the requirement for a string response from the functions, as structured data is easier to manipulate in code and we don’t have to use resources ‘stringifying’ and parsing all our content. This is due to Semantic Kernel not being aware of the planner's plan before it is in action, making it so that all responses need to be compatible with an LLM call, which defaults to text.
Code plugins
Code plugins expand functionality by granting the LLM new “skills” it did not have access to prior.
The function is a standard Python function. To transform this to a code input we added the function decorator called kernel_function. This decorator expects 2 arguments:
name, which is the name of the function to be referenced when attaching the plugin.
description, which is a string value that indicates what the intention of the function is. This helps the planner identify when it needs to call this function and when it should avoid it.
The two main use cases for code plugins are the data based on the developer’s intention, or accessing external APIs. We demonstrate both abilities below:
Accessing an external API
import yfinance as yf
import pandas as pd
from semantic_kernel.functions.kernel_function_decorator import kernel_function
# defines this function as a plugin function
@kernel_function(
name="financial_info",
description="gets the historic details for a stock")
def financial_info(
self,
TICKER_AND_PERIOD):
if not TICKER_AND_PERIOD:
raise Exception("No ticker value provided")
args = json.loads(TICKER_AND_PERIOD)
ticker_name = args["ticker_name"]
period = args["period"]
if ticker_name is not None:
ticker = yf.Ticker(ticker_name)
time = period if period is not None else '1y'
data = ticker.history(period = time)
data.index = data.index.strftime('%Y-%m-%d')
data["Close"] = data["Close"].round(4)
print('data retrieval complete')
return data.to_json()As shown in the code snippet above, we want to retrieve the historical data for a specific ticker using the Yahoo Finance API.
We created the base function for it when we instantiate a Ticker based on the input. Notice that the model is able to convert the string input to the required variables, before calling the plugins.
Then, we use the historical data to get the closing prices for the period specified. Finally, we manipulate the pandas DataFrame to format the style of the columns Close and the date index as these will be used in future steps of the process.
Processing data
import yfinance as yf
import pandas as pd
from semantic_kernel.functions.kernel_function_decorator import kernel_function
@kernel_function(name="drawdown", description="Calculate the drawdown values for the stock")
def drawdown(self, data_json: Annotated[str, "the data from the stock"]):
data = pd.read_json(StringIO(data_json))
data['Peak'] = data['Close'].cummax()
data['Drawdown'] = data['Close'] - data['Peak']
data = data.drop(columns=["Peak"])
print('drawdown calculated')
return str(data.to_json(orient='split'))We want to calculate the drawdown for the data based on the formula: drawdown = current - cummax. Pandas provides us with the functionality required to perform this calculation.
Our original data looked like this:
| Date | Close |
|---|---|
| 2024-01-01 | 102.01 |
| 2024-01-02 | 101.02 |
After the function run our data looks like this:
| Date | Close | Drawdown |
|---|---|---|
| 2024-01-01 | 102.02 | 0 |
| 2024-01-02 | 101.01 | -1.01 |
Now that we have our data available, we will be moving to a prompt plugin to generate dynamic code.
Prompt plugins
Prompt plugins are used to alter the original intention of the LLM being invoked by providing it with new instructions. The plugin files are a prompt file and a JSON file. The prompt is the instructions that the LLM must abide by. The JSON file contains the LLM values to take into account.
The content of these files looks like this:
You are a chatbox that will retrieve the ticker_name and the period
(if provided) for the company in input in a json format
Example:
query: Give me details on Apple over the last year
result: ticker_name = NVDA, period= 1y
query: Give me details on Nvidia
result: ticker_name = NVDA, period= null
query: What colour is the sky
result: No ticker available
input={{$user_input}}{
"schema": 1,
"description": "From the data generate code that will map the data over a time period",
"execution_settings": {
"default": {
"max_tokens":4096,
"temperature": 0.1,
"stop_sequences": [
"[Done]"
]
}
}
}The keyword filenames skprompt and config will let the planner know that these are prompt plugins. The prompt file will contain a straight prompt instruction similar to an LLM Model system message, which provides instructions to the model.
The config file will determine the kwargs information for the prompt. This is the equivalent of writing the below code but with the correct mappings, and the input required based on the part of the goal this step is aiming to achieve:
f = open('skprompt.txt', 'r')
response = client.chat.completions.create(
model=current_model,
messages=[
{"role": "system", "content": f.read()},
{"role": "user", "content": "user_input": user_input}
],
temperature=0.1,
max_tokens=4096,
stop=stop_sequence,
)The plugins are then attached to the kernel instance before we instantiate the planner. Hence, any planners we may have will benefit from the plugins provided.
Conclusion
Various tools are available to create GenAI agents for specific tasks, each with its strengths and weaknesses. Semantic Kernel is an interesting tool for creating straightforward agents that perform relatively well for simple tasks.
As illustrated above, we can use Semantic Kernel to quickly create AI agents that can retrieve and modify data as well as perform LLM requests to accomplish a predetermined goal. Semantic Kernel is capable of utilising the LLM to create the best approach to a task and which plugins to consume to ensure the task is completed.
The two main advantages explored in this article are Plugins and Planners. Plugins are versatile and powerful and require minimal alteration to functions for code plugins, and standard text values for prompt plugins. The variety of the planners and the ease of creation makes them very reliable for different types of agents.


Insight, imagination and expertly engineered solutions to accelerate and sustain progress.
Contact