An introduction to ETL and Azure Data Factory
ETL and Azure Data Factory both play a key role in extracting value from your data

In today’s data-driven world, extracting, transforming, and loading (ETL) processes play a vital role in managing and analysing large volumes of data. ETL is a crucial process in data integration and analytics, enabling businesses to extract data from various sources, transform it into a consistent and meaningful format, and load it into a target system for analysis, reporting, or other purposes.
Ensuring that this process is respected, repeatable, and reliable is essential. There are great tools that achieve this and in this blog post we introduce one of the best options for you — the Azure Data Factory (ADF).
Who is this post for?
Whether you are seeking to understand the basics concepts about ETL or learn which Azure service might be used to handle this process, you are reading the right post!
And if you’ve never heard of ETL or ADF, no worries, it is a good opportunity to enhance your knowledge. I will explain what ETL is and what Azure Data Factory is.
It is important to know that this blog post gives an overview of ETL and Azure Data Factory and their proposals. I’m afraid to say there are not any hands-on, expert scenarios. However, you will get a simple scenario as an example of how to work with ETL and ADF.
So, what is ETL?
Before diving into Azure Data Factory, let’s quickly recap the basic concepts of ETL.
ETL refers to a three-step process: extracting data from various sources, transforming it into a consistent format, and loading it into a target destination. This process ensures that data is properly prepared for analysis, reporting, or other downstream operations.
The ETL process serves as the foundation for data integration, ensuring that data is accurate, consistent, and usable across different systems and applications. It involves several key steps that work together to shape raw data into valuable insights. Let’s take a closer look at each phase of the ETL process:
Extraction
The extraction phase involves gathering data from simple or multiple sources, which can include databases, files, web services, APIs, cloud storage, and more. This step typically requires understanding the structure, format, and accessibility of the source data. Depending on the source, extraction methods can range from simple data exports to complex queries or data replication techniques.
Transformation
After data is extracted, it often requires cleansing, filtering, reformatting, and combining with other datasets to ensure consistency and quality. This phase involves applying various data transformation operations, such as data cleaning, normalisation, validation, enrichment, and aggregation. Transformations may also involve complex business rules, calculations, or data validation against reference data.
Loading
Once the data is transformed and prepared, it is loaded into a target system or destination. The target can be a data warehouse, a database, a data lake, or any other storage infrastructure optimised for analytics or reporting. Loading can be done in different ways, including full loads (replacing all existing data), incremental loads (updating or appending only new or changed records), or a combination of both.
ETL pipelines can have different loading strategies, such as batch processing (scheduled at specific intervals) or real-time processing (triggered by events or changes in the data source). The choice of loading strategy depends on the data requirements, latency needs, and overall system architecture.
Validation and quality assurance is required throughout the ETL process
Throughout the ETL process, data quality and integrity are of utmost importance. It is crucial to perform data validation checks, ensuring that the transformed data meet predefined quality standards. Validation includes verifying data completeness, accuracy, consistency, conformity to business rules, and adherence to data governance policies. Any data that fails validation can be flagged, logged, or even rejected for further investigation.
ETL and modern
data integration
As data volumes and complexity continue to increase, modern data integration platforms, such as Azure Data Factory, have emerged to streamline and automate the ETL process. These platforms offer visual interfaces, pre-built connectors, and scalable infrastructure to facilitate data extraction, transformation, and loading tasks. They also integrate with other tools and technologies, such as data lakes, big data processing frameworks, and cloud services, to enable advanced analytics and insights.
By using the ETL process, you can achieve successful data integration. This enables organisations to extract data from various sources, transform it into a consistent format, and load it into a target system for analysis and reporting. ETL plays a critical role in ensuring data quality, consistency, and reliability. With the advent of modern data integration platforms like Azure Data Factory, organisations can leverage advanced capabilities and automation to streamline their ETL workflows, unlocking the true value of their data assets.
Introducing the
Azure Data Factory
Now we know more about the ETL process, the question is: which tool could you use to configure this process? This is where we introduce the Azure Data Factory (ADF).
Azure Data Factory is a fully managed cloud service that enables organisations to orchestrate and automate data integration workflows at scale. It provides a rich set of tools and capabilities to build ETL pipelines, allowing you to extract data from diverse sources, transform it using powerful data transformation activities, and load it into target systems or data warehouses.
Azure Data Factory is a cloud-based data integration service offered by Microsoft Azure. It provides a scalable and fully managed platform for orchestrating and automating data movement and transformation workflows. With ADF, organisations can easily extract data from various sources, transform it using powerful data transformation activities, and load it into target destinations, such as data lakes, databases, and analytics platforms.

Key features and benefits
of Azure Data Factory
Connectivity to diverse data sources
Below, we’ve highlighted the most important features and benefits of ADF.
Connectivity to diverse data sources
ADF supports a wide range of data sources and platforms, including on-premises databases, cloud-based services (such as Azure SQL Database, Azure Blob Storage, and Azure Data Lake Storage), Software-as-a-Service (SaaS) applications (like Salesforce and Dynamics 365), and popular big data frameworks (such as Hadoop and Spark). This versatility allows organisations to integrate data from multiple systems seamlessly.
Visual interface for pipeline orchestration
ADF provides a user-friendly graphical interface, known as the Azure Data Factory portal, which enables users to design, monitor, and manage their data integration pipelines. The portal offers drag-and-drop functionality, allowing users to easily create workflows, define dependencies between activities, and set up scheduling and triggering mechanisms.
Data transformation capabilities
ADF includes a rich set of data transformation activities to clean, transform, and enrich data during the ETL process. These activities can be used to perform operations such as data filtering, mapping, aggregation, sorting, and joining. ADF also supports custom data transformations using Azure Functions or Azure Databricks, enabling advanced data processing scenarios.
Scalability and parallelism
Azure Data Factory leverages the scalability and elasticity of the Azure cloud infrastructure. It can dynamically scale resources based on workload demands, allowing for efficient processing of large volumes of data. ADF can also parallelise data movement and transformation activities, enabling faster execution and improved performance.
Integration with Azure services and ecosystem
ADF seamlessly integrates with other Azure services, providing extended capabilities and flexibility. For example, you can incorporate Azure Machine Learning for advanced analytics, Azure Logic Apps for event-based triggers, Azure Databricks for big data processing, and Azure Synapse Analytics for data warehousing and analytics.
Monitoring, logging, and alerts
ADF offers comprehensive monitoring and logging capabilities to track pipeline execution, diagnose issues, and analyse performance. It provides built-in dashboards, metrics, and logs for monitoring data movement, activity execution, and pipeline health. Additionally, ADF supports alerts and notifications, allowing users to set up email or webhook notifications based on predefined conditions or errors.
Workflow orchestration and scheduling
Data Factory provides a visual interface for designing and orchestrating complex ETL workflows. It allows you to define dependencies, execute activities in parallel or sequence, and schedule data integration tasks based on your requirements.
Attention point
When Azure Data Factory is created it’s exposed to the internet, but there is the possibility to configure it to be private. In terms of the “public” and “private” aspects of Azure Data Factory, here’s what they generally refer to:
Public Data Factory
A public data factory refers to an Azure Data Factory instance that is accessible over the public internet. It means that the Data Factory can be accessed and used by users or applications outside of your private network. Public Data Factories are typically used when you need to integrate data across different cloud platforms, on-premises systems, or when you want to expose your data integration pipelines as a service to external consumers.
Private Data Factory
A Private Data Factory refers to an Azure Data Factory instance that is deployed within your private network or virtual network (VNet). It is isolated and not directly accessible over the public internet. Private Data Factories are used when you need to securely integrate data within your private network or when you want to restrict access to your data integration pipelines within your organisation.
Azure Data Factory is ideal for streamlining ETL processes and unlocking the value of data assets
Azure Data Factory is a powerful cloud-based data integration service that simplifies the process of orchestrating, automating, and managing data movement and transformation workflows. Its flexibility, scalability, and integration with other Azure services make it an ideal choice for organisations looking to streamline their ETL processes and unlock the value of their data assets.
Whether you need to integrate on-premises data sources, cloud-based services, or big data platforms, Azure Data Factory provides the tools and capabilities to handle your data integration requirements efficiently and effectively.
Building an ETL pipeline with Azure Data Factory
To illustrate the process of building an ETL pipeline, let’s consider a hypothetical scenario. Suppose you need to extract customer data from an on-premises database, perform some data transformations, load the transformed data into Datalake and then use Azure Synapse Analytics for further analysis.

Creating data integration pipelines
In Azure Data Factory, you define a pipeline that consists of activities representing the ETL steps. You can use pre-built connectors and activities to connect to your data source, perform transformations using built-in or custom code, and load the data into the target destination.
Mapping and transforming data
Azure Data Factory provides a graphical interface for defining data mappings and transformations. You can apply transformations such as filtering, sorting, aggregating, and joining data to transform it into the desired format. You might use Azure DataLake as storage for those dates since the raw data till the structured data.
Monitoring and managing pipelines
Once the pipeline is deployed, you can monitor its execution, track data movement, and troubleshoot any issues using Azure Data Factory’s monitoring and management features. A simple task list for configuring Azure Data Factory’s monitoring and management features.
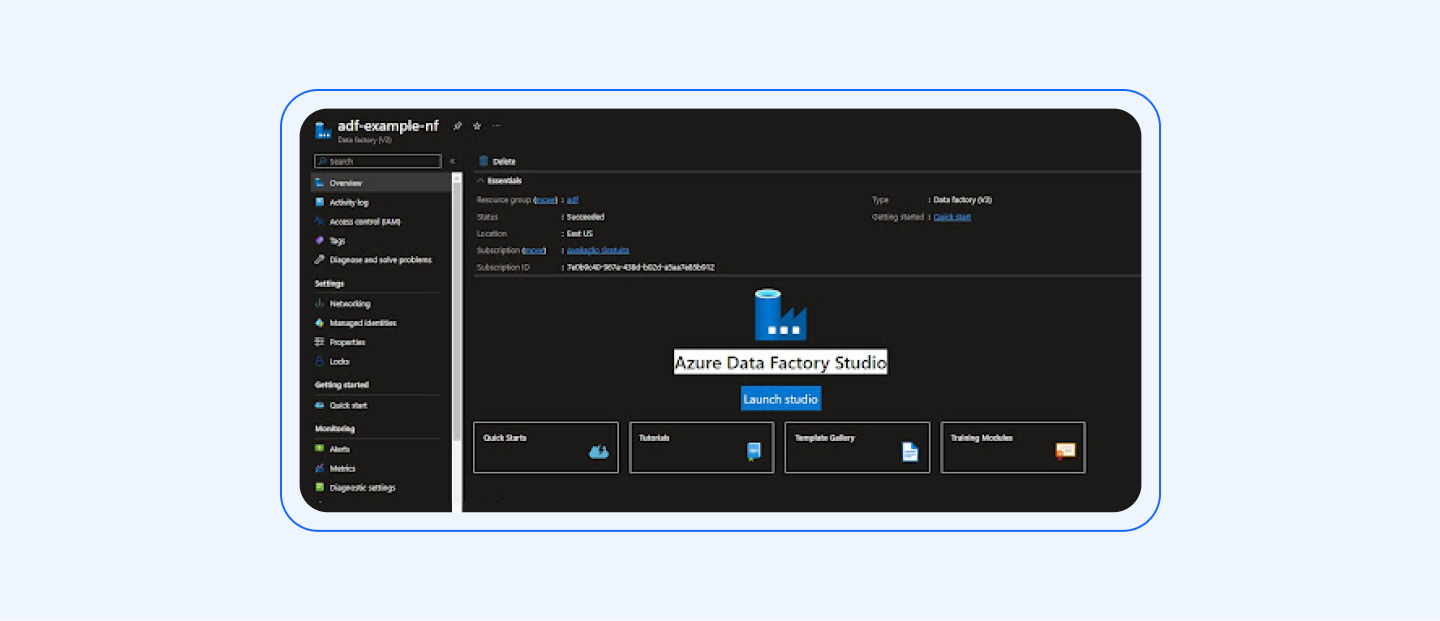
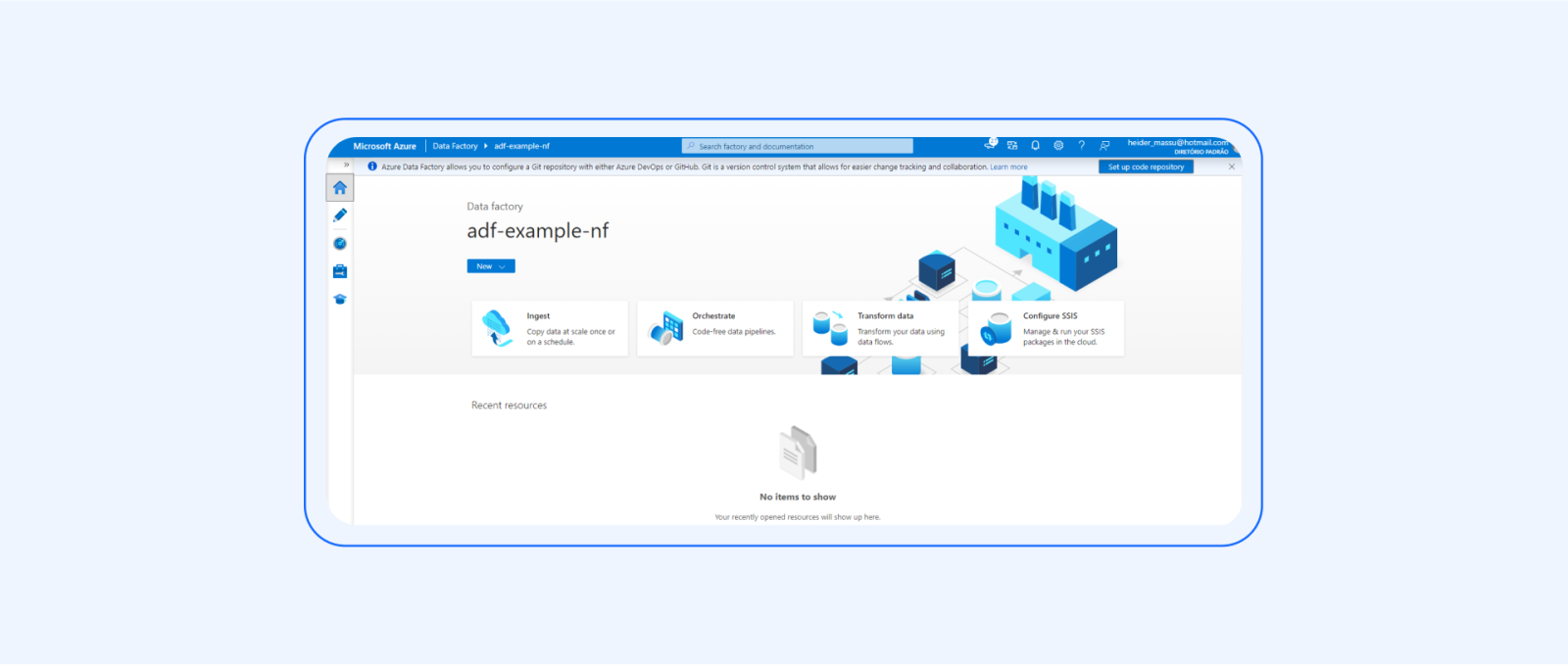
1. Set up the Azure Data Factory:
Create an Azure Data Factory instance in the Azure portal:
Configure the required settings, such as the region, resource group, and integration runtime.
2. Set up the Azure DataLake:
Create an Azure DataLake in the Azure portal:
Configure different blobs for each kind of data or phase. Eg:
Blob container for raw data
Blob container for enriched data
Blob container for refined data
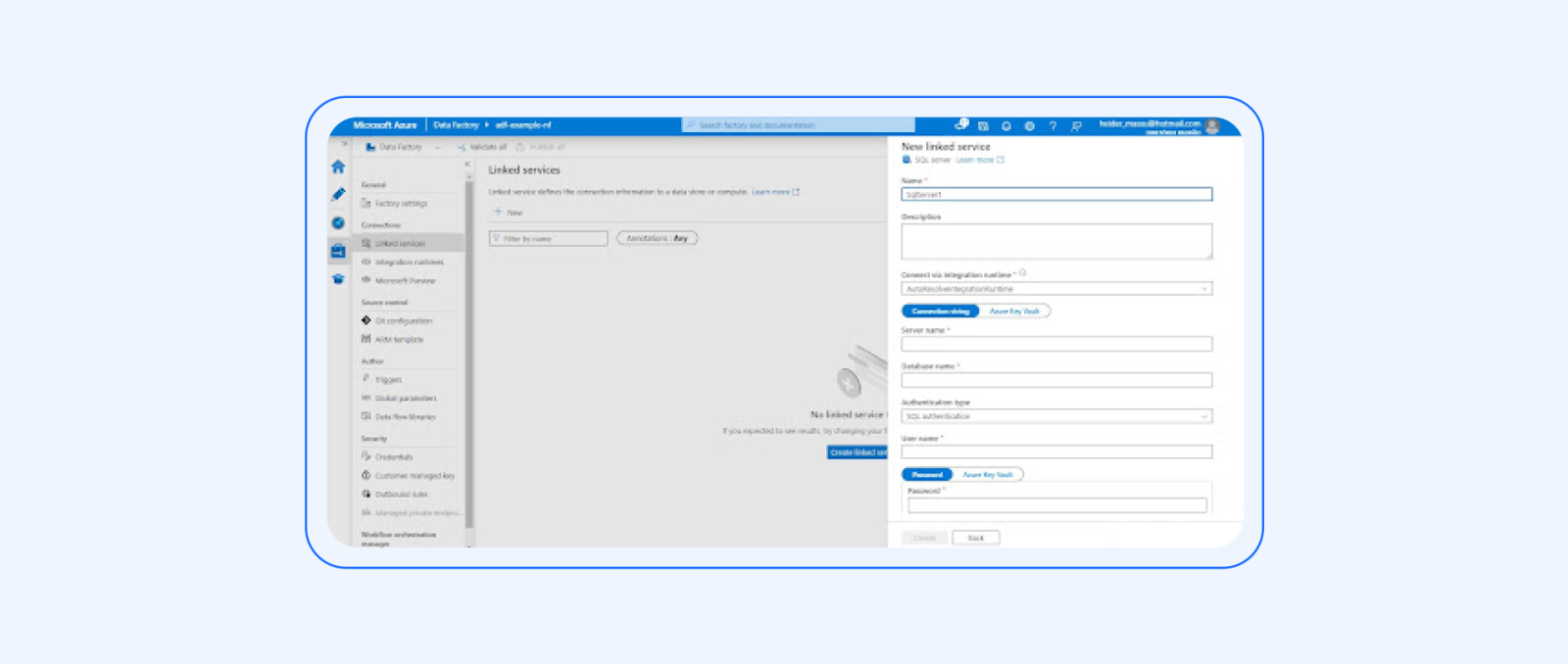
3. Define Linked Services:
It’s necessary to have a VPN or ExpressRoute to have communication between those different environments and then use the linked service.
Create a linked service to connect to the on-premises database, the source in this case. This involves providing the necessary connection details, such as server name, credentials, and database name.
Create a linked service for Azure Synapse Analytics, specifying the connection details for the target destination.
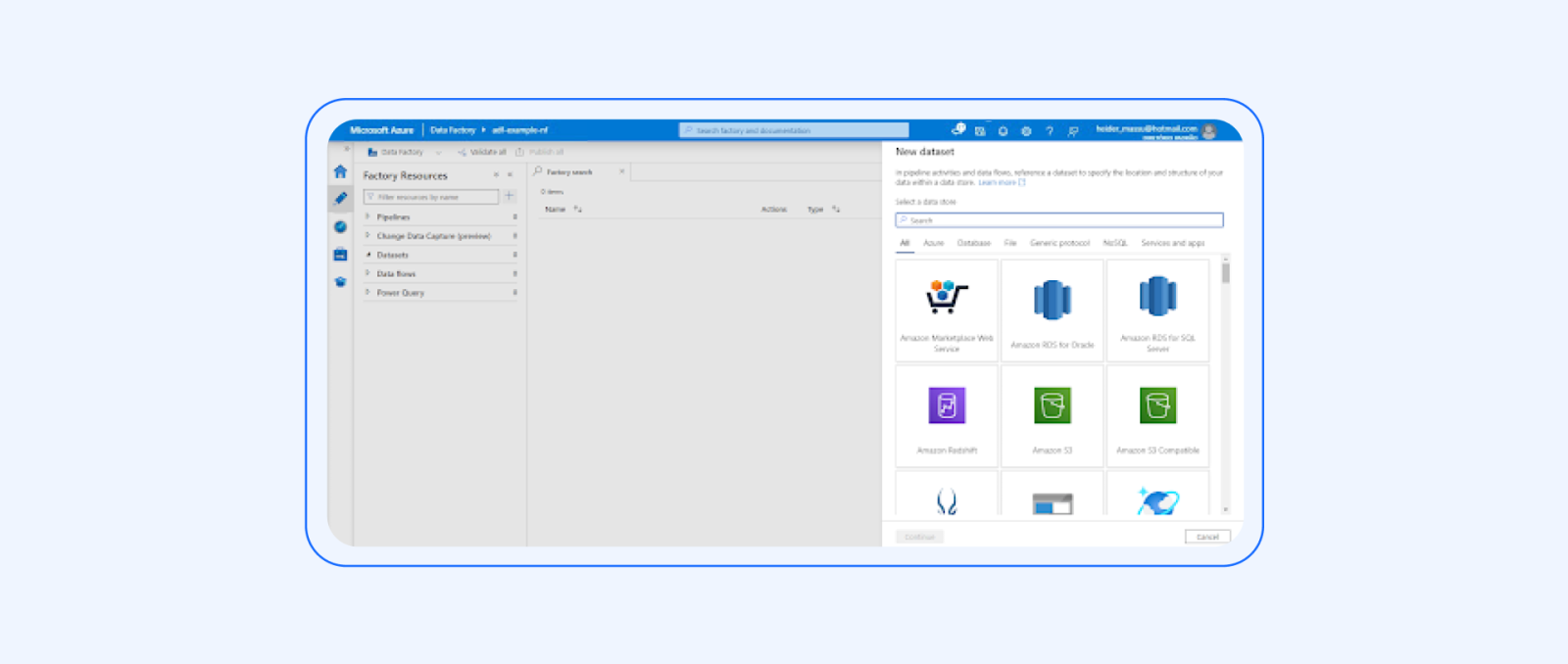
4. Create the datasets:
Define a dataset for the source data in the on-premises database. Specify the connection information and the structure of the data.
Create a dataset for Azure Synapse Analytics and Azure DataLake, defining the connection details and the target structure.
5. Build the pipeline:
Create a new pipeline in Azure Data Factory.
Add a copy activity to the pipeline. Configure the source dataset as the on-premises database and the destination dataset as Azure DataLake.
Specify the data mapping and transformation activities within the copy activity. This can include column mapping, data filtering, aggregations, or other transformations.
Configure any required data transformation activities, such as data cleansing, enrichment, or formatting.
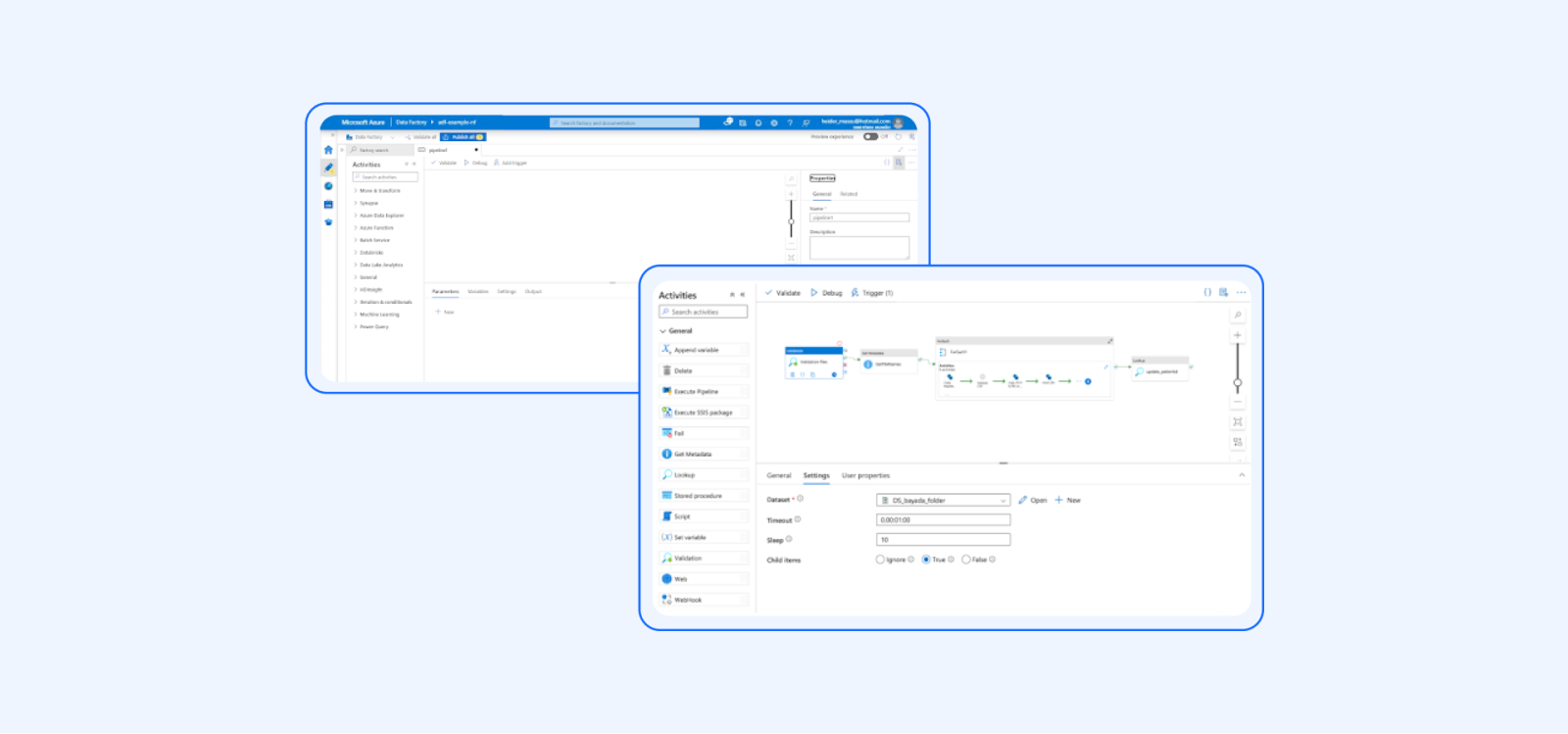
6. Define dependencies and scheduling:
Define any dependencies between activities within the pipeline, ensuring that activities are executed in the correct sequence.
Set up a schedule for the pipeline to determine when it should run, whether it’s a one-time execution or a recurring schedule — e.g., daily, hourly, etc.
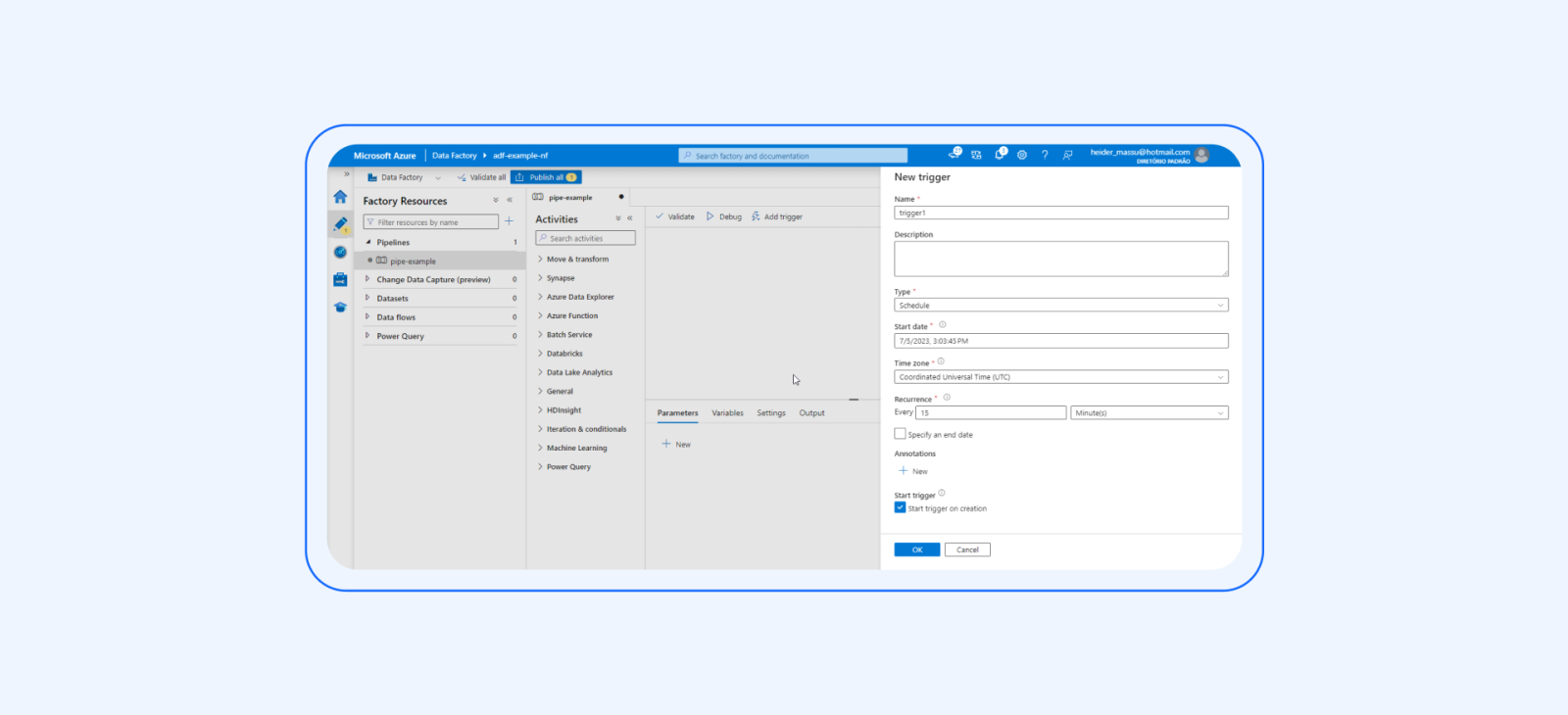
7. Monitor and execute the pipeline:
Deploy and validate the ETL pipeline.
Monitor the execution of the pipeline using Azure Data Factory’s monitoring capabilities.
Track the progress, identify any errors or issues, and troubleshoot as necessary.
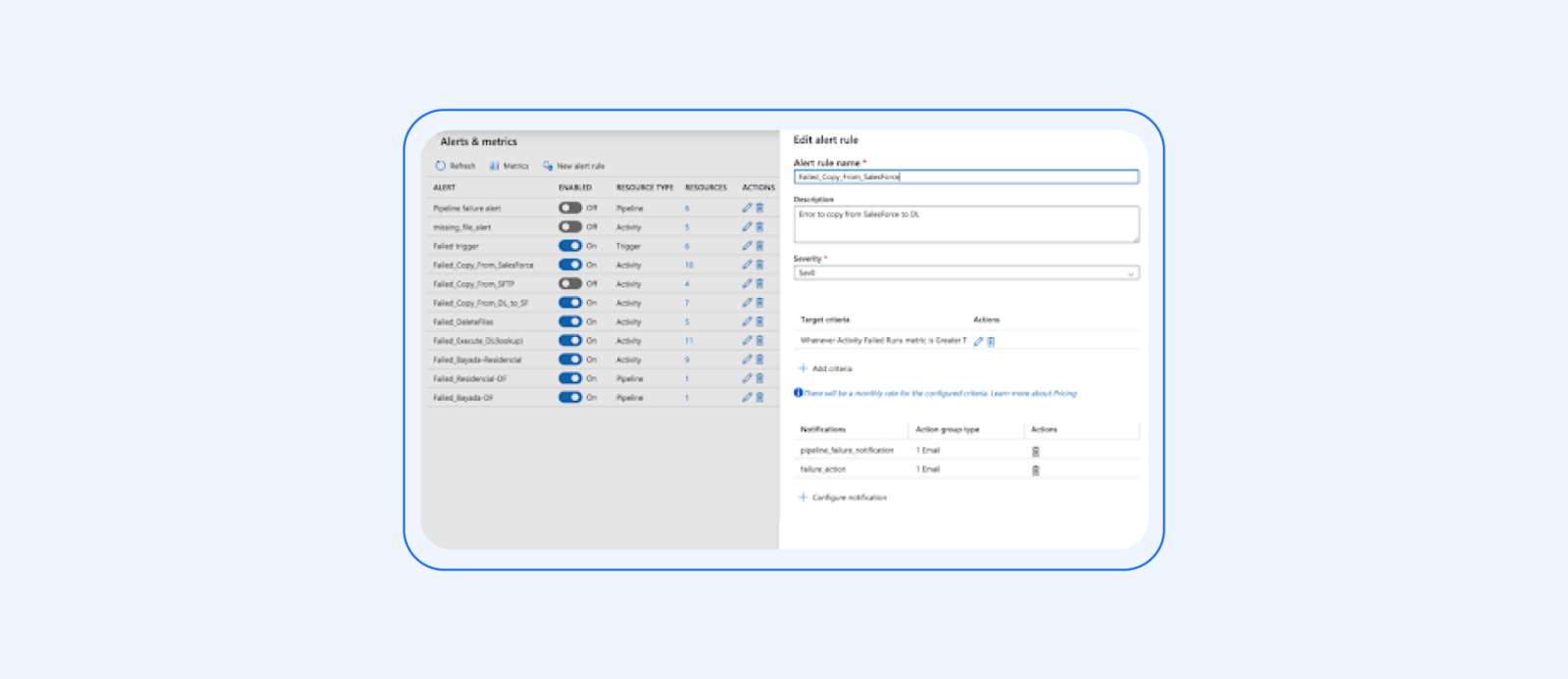
8. Validate and verify the results:
Verify that the customer data has been successfully extracted from the on-premises database.
Confirm that the data has been transformed according to the defined mappings and transformations.
Validate that the transformed data has been loaded into Azure Synapse Analytics as expected.
By following these steps, you can build an ETL pipeline in Azure Data Factory to extract customer data from an on-premises database, apply necessary transformations, and load the transformed data into Azure Synapse Analytics for further analysis and reporting.
Advanced features and integration
Apart from the core ETL capabilities, Azure Data Factory integrates seamlessly with other Azure services, such as Azure Databricks, Azure Machine Learning, and Azure Logic Apps. This integration enables you to leverage advanced analytics, machine learning, and event-driven workflows within your ETL pipelines.
Conclusion
This blog post has provided an introduction to extracting, transforming, and loading (ETL) processes and Azure Data Factory (ADZ).
By leveraging Azure Data Factory, organisations can streamline their ETL processes and unlock the value of their data assets. Whether integrating on-premises data sources, cloud-based services, or big data platforms, ADF provides the necessary tools and capabilities to handle data integration requirements efficiently.
The next step is for you to explore Azure Data Factory and consider building your own ETL pipeline, when the time is right. With the flexibility and scalability offered by ADF, you can harness the full potential of your data for insights and informed decision-making.
References and links
https://learn.microsoft.com/en-us/azure/data-factory/introduction
https://learn.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-introduction
https://learn.microsoft.com/en-us/azure/architecture/data-guide/relational-data/etl
https://www.microsoft.com/en-gb/industry/blog/technetuk/2020/11/26/how-to-eliminate-azure-data-factorys-public-internet-exposure-using-private-link/
https://learn.microsoft.com/en-us/azure/data-factory/managed-virtual-network-private-endpoint


Insight, imagination and expertly engineered solutions to accelerate and sustain progress.
Contact